I have to admit that I probably missed or misinterpreted the presentation of this course contents.
What I expected was a sort of overview of the "new" database paradigms (including the whole NOSQL family of products) and/or some generally applicable design and architectural guidelines on how to implement solutions using these.
Well, that's not what this course is about, frankly.
What this is about is the history and the design decisions that lead to build HANA-DB a special in-memory, columnar DB created by SAP AG.
The course itself is held, for the most part, by Prof. Hasso Plattner - cofounder of SAP itself and "father" of the whole HANA-DB project.
Was this still interesting, considering that the focus is just on one specific product? Definitely yes, because it explains very clearly the challenges and the design compromises the team had to face, and it illustrates the benefits that using such a product could entail (basically removing the split between OLAP an OLTP).
What I found lacking, instead, was any concrete example of what kind of changes or idioms you should expect when designing/coding against such a DB. In a sense, the answer is "none" because HANA-DB uses perfectly standard SQL and may easily become a drop-in replacement for more traditional RDBMS (actually no, there is a very simple thing you must remember when writing your queries: do not use "select * from..." and always explicitly mention all and only the fields you need to retrieve - that's all).
There is probably more, but I since found out that there is a dedicated course for that (offered by the open.SAP online education initiative).
The course is structured as a series of short-to-medium videos, interleaved with short quizzes about the previous video. At the end of the week sequence you get another quiz (this one counts for the final grade). At the end of the whole series of lessons you get a longer quiz, which counts for 50% of the final grade (the other 50% comes from the weekly quizzes).
All quizzes are of the multiple choice variety, and grading is fully automated.
Final Result: 85%. Even if I never had any exposure to Columnar or In-Memory DB before this course I have a fairly good experience with DB in general, so the various questions were never really hard for me. The grade may look "low" but I basically just breezed through each quiz, including the final exam. Had I devoted more time to refresh the various topics the result would have been a good 10% higher.
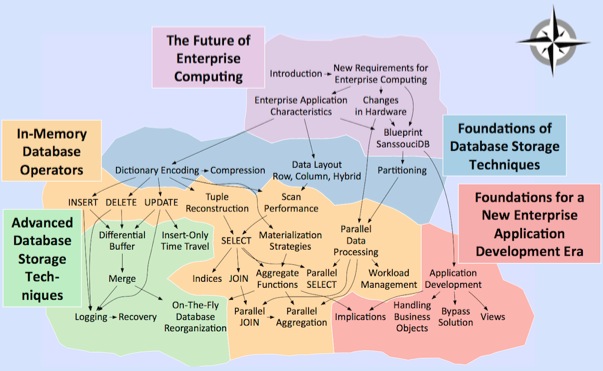
Course Syllabus
Introduction
New Requirements for Enterprise Computing
Enterprise Application Characteristics
Changes in Hardware
A Blueprint of SanssouciDB
Week 2: Foundations of Database Storage Techniques and In-Memory Database Operators Part 1
Dictionary Encoding
Compression
Data Layout in Main Memory
Partitioning
Delete
Insert
Update
Tuple Reconstruction
Scan Performance
Week 3: Advanced Database Storage Techniques and In-Memory Database Operators Part 2
Select
Materialization Strategies
Differential Buffer
Insert-only
Merge
Parallel Data Processing
Indices
Join
Aggregate Functions
Parallel Select
Week 5: Further Optimizations and Recovery
Workload Management
Parallel Join
Parallel Aggregation
Logging
Recovery
On-the-fly Database Reorganization
Week 6: Foundations for a New Enterprise Application Development Era
Implications
Views
Handling Business Objects
Bypass Solution
Excursion 1: Aggregate Caching
Excursion 2: Point of Sale Explorer
Week 7 and 8: Final Exam